Introduction to probability and distribution
Introduction
This section will introduce the basic of probability, probability calculation for events arising from random processes and probability distributions.
Probability is a course in itself, but in here, we will just be touching on the fundamentals that are relevant for providing a conceptual framework for statistical inference.
Random Process
Let's start with the definition of random process. In a random process we know what outomes could happen, but we don't know which particular outcome will happen.
Some example of random processes are:
- Coin tosses - We know it can land on hands or tails, but we don't know which one.
- Die rolls - We know there are 6 possible outomes, but we don't know which is next one.
- Shuffle mode on your music player - You know next song will be something from your entire music library. But, you don't know which song will play next.
- The stock market - Sometimes it can be helpful to model a process as random even if it is not truly random. The stock market is an example of model a random process.
Probability Basic
When discussing probability of events, we generally use the notation P(A) to indicate the probability of event A.
There are several possible interpretations of probability but they almost completely agree on the mathematical rules probability must follow:
0 ≤ P(A) ≤ 1
Probability of an event is always between 0 and 1. So if you get a probability result less than 0 or greater than 1, you know that you made a mistake.
The traditional definition of probability is a relative frequency. This is the frequentist interpretation of probability, where the probability of an outcome is the proportion of thimes the outcome would occur if we observed the random process an infinite number of times. An alternative interpretation is the bayesian interpretation. A bayesian interpret a probability as a subjective degree of belief. For the same event, two separate people could have different viewpoints and so assign different probabilities to it. This interpretation allows for prior information to be integrated into the inferential framework. Bayesian methods have been largely populrized by revolutionary advances in computational technology and methods during the last 20 years.
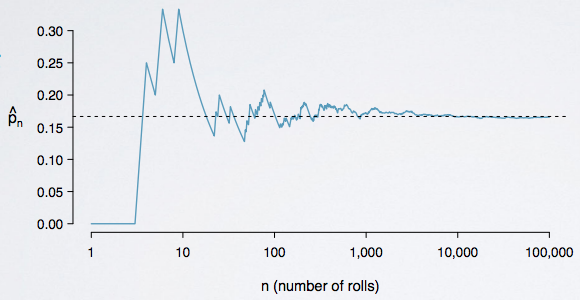
Law of large numbers
Law of large numbers states that as more observations are collected, the proportion of occurences with a particular outcome converges to the probability of that outcome.
This is why we roll the fair die few times, we might not exactly get each number to settle down to one sixth. But, if we roll the die, for example 6000 times, we would expect to see about one sixth of the time to get each number.
Latest Post
- Dependency injection
- Directives and Pipes
- Data binding
- HTTP Get vs. Post
- Node.js is everywhere
- MongoDB root user
- Combine JavaScript and CSS
- Inline Small JavaScript and CSS
- Minify JavaScript and CSS
- Defer Parsing of JavaScript
- Prefer Async Script Loading
- Components, Bootstrap and DOM
- What is HEAD in git?
- Show the changes in Git.
- What is AngularJS 2?
- Confidence Interval for a Population Mean
- Accuracy vs. Precision
- Sampling Distribution
- Working with the Normal Distribution
- Standardized score - Z score
- Percentile
- Evaluating the Normal Distribution
- What is Nodejs? Advantages and disadvantage?
- How do I debug Nodejs applications?
- Sync directory search using fs.readdirSync