Data Science in Science
Methods of Inquiry
What is going on in Science:
- Empirical - For thousands of years, scientific inquiry has been empirical. You observe the natural world, or maybe in some cases replicate the natural world in a controlled environment in a laboratory. And make observations about that.
- Theoretical - In the last few hundred years science has accepted theoretical models as a valid method of inquiry. One of that is reinforcing empirical methods, so you know new theories suggests new experiments and the theories help explain the observed data that you get from the experiments.
- Computational - In the last 50 years or so high speed computation has emitted an entirely new method of scientific inquiry. Soon you can simulate in the computer phenomena on that otherwise you can't observe directly. And you can't reproduce in the lab and even the theoretical models become too complex to solve analytically using paper and pencil. Now, you can actually start from initial conditions and run the simulation to get a result.
That are the three methods of inquiry.
The emerge of eScience
In the last ten years or so, there's been arguably a fourth method of scientific Inquiry, which is to acquire massive data sets from instruments or from simulations. And then explore these data sets using new algorithms and infrastructure. And so eScience is really about massive and complex data, data large enough to require you know, automated or semi-automated analysis.
You can't look at it, you can't inspect it directly. And the relevant tools here are the same as those for data science, e.g. databases, visualization scale out computing , the new sequel systems, Machine learning techniques, Web services and so on.
The idea of the fourth paradigm has been told lots of ways. The way we like to talk about this story is that science has always been about asking questions but conventionally it was really about querying the world. You would, sort of, have data acquisition or activities, experiments or field studies. They will couple to very specific hypothesis where you have the question in mind first and we click the data.
But eScience has really shifted a bit where now you're kind of downloading data on mass, you're downloading the world first putting some sort of representation in the computer. And then creating that database to test your hypothesis and so it's the data can be acquired independent of any specific hypothesis in some case.
The development of eScience is due to:
- The cost of data acquisition has dropped precipitously. We now can acquire at enormous amounts of data at very high resolution.
- Thanks to advances in computing. The simulations you can run are getting bigger and higher resolution, producing larger and larger amounts of data.
Examples of Big Data
eScience is driven by data more than by the computation.
Large Synoptic Survey Telescope (LSST)

- 40TB/day
- 100+ PB in its 10-year lifetime
- 400mbps sustained data rate between Chile and NCSA
Illumina HiSeq 2000 Sequencer

- 1TB/day
Regional Scale Nodes of the NSF Ocean Observatories Initiative
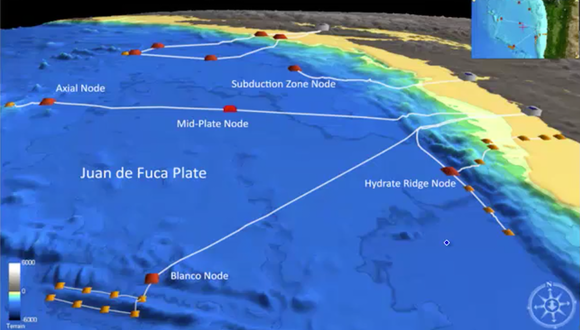
- 1000km of fiber optic cable on the seafloor
- Connecting thousands of chemical, physical, and biologial sensors.
The Web
- 20+ billion web pages x 20KB = 400+1TB
- One computer read 30-35 MB/sec from one disk would have to take > 4 months just to read the web
What is eScience?
eScience is about the analysis of data
- The automated or semi-automated extraction of knowledge from massive volumes of data
- There is simply too much of it to look at
- But it's not just a matter of volume
- The three V's of Big Data
- - Volume: number of rows/objects/bytes
- - Variety: number of columns/dimensions/sources
- - Velocity: number of rows/bytes per unit time
- More V's
- - Veracity: Can we trust this data?
Summary
Science is in the midst of a generational shift from a data-poor enterprise to a data-rich enterprise.
Data analysis has replaced data acquisition as the new bottleneck to discovery.
What does this have to do with business? Business is beginning to look a lot like science.
- Acquire data aggrssively and keep it around.
- Hire data scientists.
- Make empirical decisions.
Latest Post
- Dependency injection
- Directives and Pipes
- Data binding
- HTTP Get vs. Post
- Node.js is everywhere
- MongoDB root user
- Combine JavaScript and CSS
- Inline Small JavaScript and CSS
- Minify JavaScript and CSS
- Defer Parsing of JavaScript
- Prefer Async Script Loading
- Components, Bootstrap and DOM
- What is HEAD in git?
- Show the changes in Git.
- What is AngularJS 2?
- Confidence Interval for a Population Mean
- Accuracy vs. Precision
- Sampling Distribution
- Working with the Normal Distribution
- Standardized score - Z score
- Percentile
- Evaluating the Normal Distribution
- What is Nodejs? Advantages and disadvantage?
- How do I debug Nodejs applications?
- Sync directory search using fs.readdirSync