Experimental Design and Random Sample Assignment
Principles of Experimental Design
- Control: Compare treatment of interest to a control group;
- Randomize: Randomly assign subjects to treatments;
- Replicate: Within a study, replicate by collecting a sufficiently large sample, or replicate the entire study;
- Block: If there are variables that are known or suspected to affect the response variable, first group subjects into blocks based on these variables, and then randomize cases within each block to treatment groups;
More on blocking
We would like to design an experiment to investigate if energy gels make you run faster:
- Treatment: energy gel;
- Control: no energy gel;
It is suspected that energy gels might affect pro and amateur athletes differently, therefore we block for pro status:
- Divide the sample to pro and amateur;
- Randomly assign pro and amateur athletes to treatment and control groups;
- Pro and amateur athletes are equally represented in the resulting treatment and control groups;
This way, if we do find a difference in running speed between the two groups, we will be able to attribute it to the treatment, the energy gel, and can be assured that the difference isn't due to pro status, since both pro and amateur athletes were equally represented in the treatment and control groups.
Blocking vs. Explanatory variables
- Explanatory variables (also sometimes called factors) are conditions we can impose on the experimental units.
- Blocking variables are characteristics that the experimental units come with, that we would like to control for.
- Blocking is like stratifying, except used in experimental settings when randomly assigning, as opposed to when sampling.
More Experimental Design Terminology
- Placebo: fake treatment, often used as the control group for medical studies;
- Placebo effect: experimental units showing improvement simply because they believe they are receiving a special treatment;
- Blinding: when experimental units do not know whether they are in the control or treatment group;
- Double-blind: when both the experimental units and the researchers do not know who is in the control and who is in the treatment group;
Random Sample vs. Random Assignment
Random Sampling
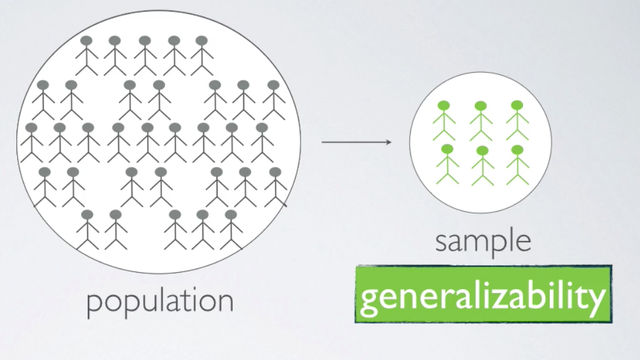
If subjects are selected randomly from the population, then each subject in the population is equally likely to be selected and the resulting sample is likely representative of the population. Therefore the study's results are generalizable to the population at large.
Random Assignment
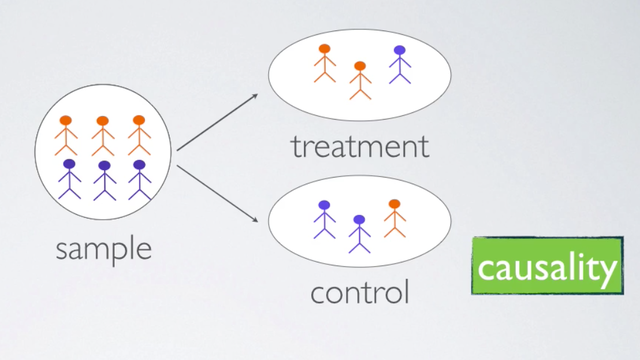
Random assignment occurs only in experimental settings where subjects are being assigned to various treatments. Taking a close look at our sample, we usually see that the subjects exhibits slightly different characteristics from one another. Through a random assignment, we ensured that these characteristics are represented equally in the treatment and control groups. This allows us to attribute any observed difference between the treatment and control groups, to the treatment being imposed on the subjects since otherwise these groups are essentially the same. In other words, random assignment allows us to make causal conclusions based on this study.
Example
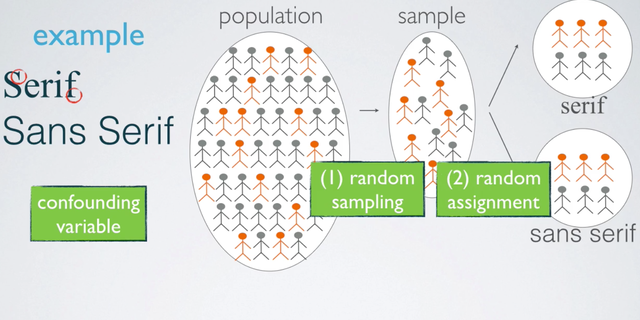
Let's give it a quick example, suppose we want to conduct a study evaluating whether people read Serif fonts or Sans Serif. In other words, without Serif fonts faster. Note that Serifs are these small decorative pieces on the ends of each character. Ideally, you first randomly subjects for your study from your population. Then you assign the subjects in your sample to two treatment groups. One where they read some text in serif font and the other where they read the same text in Sans Serif font. Through random assignment, we ensure that other factors that may be contributing to reading speed, indicated here with the different colors for the subject.
For example, fluency or how often the subject reads for leisure, are represented equally in the two groups. We call such variables con-founders or confounding variables. In this setting, if we observe any difference between the average reading speeds of the two groups, we can actually attribute it to the actual treatment, the font type, and know that it its likely not due to the control confounding variable. So to recap, sampling happens first and assignment happens second.
Conclusions
So, in summary, a study that employs random sampling and random assignment can be used to make causal conclusions. And these conclusions can be generalized to the whole population. This would be an ideal experiment, but such studies are usually difficult to carry out, especially if the experimental units are humans, since it may be difficult to randomly sample people from the population and then impose treatments on them. This is why most experiments recruit volunteer subjects. You may have seen ads for these on a university campus or in a newspaper. Such human experiments that rely on volunteers employ random assignment but not random sampling. These studies can be used to make causal conclusions, but the conclusions only apply to the sample and the results cannot be generalized. A study that uses no random assignment but does use random sampling, is your typical observational study. Results can only be used to make correlation statements, but they can be generalized to the whole population. A final type of study, one that doesn't use random assignment or a random sampling, aan only be used to make correlational statements, and these conclusions are not generalizable. This is an un-ideal observational study.

References & Resources
- N/A
Latest Post
- Dependency injection
- Directives and Pipes
- Data binding
- HTTP Get vs. Post
- Node.js is everywhere
- MongoDB root user
- Combine JavaScript and CSS
- Inline Small JavaScript and CSS
- Minify JavaScript and CSS
- Defer Parsing of JavaScript
- Prefer Async Script Loading
- Components, Bootstrap and DOM
- What is HEAD in git?
- Show the changes in Git.
- What is AngularJS 2?
- Confidence Interval for a Population Mean
- Accuracy vs. Precision
- Sampling Distribution
- Working with the Normal Distribution
- Standardized score - Z score
- Percentile
- Evaluating the Normal Distribution
- What is Nodejs? Advantages and disadvantage?
- How do I debug Nodejs applications?
- Sync directory search using fs.readdirSync