Fuzzy c-Means
Introduction
Fuzzy c-means (FCM) is a method of clustering which allows one piece of data to belong to two or more clusters. This method (developed by Dunn in 1973 and improved by Bezdek in 1981) is frequently used in pattern recognition. Straightly speaking, this algorithm works by assigning membership to each data point correspoinding to each cluster center on the basis of distance between the cluster and the data point. More the data is near to the cluster center more is its membership towards the particular cluster center. Clearly, summation of membership of each data point should be equal to one. The algorithm is based on minimization of the following objective function:
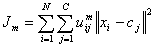 ,
, 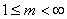
where m (the Fuzziness Exponent) is any real number greater than 1, N is the number of data, C is the number of clusters, uij is the degree of membership of xi in the cluster j, xi is the ith of d-dimensional measured data, cj is the d-dimension center of the cluster, and ||*|| is any norm expressing the similarity between any measured data and the center.
Fuzzy partitioning is carried out through an iterative optimization of the objective function shown above, with the update of membership uij and the cluster centers cj by:
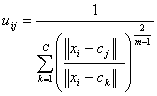
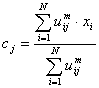
where ||xi - cj|| is the Distance from point i to current cluster centre j, ||xi - ck|| is the Distance from point i to other cluster centers k.
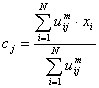
The iteration will stop when 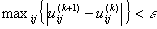 , where ε is a termination criterion between 0 and 1, whereas k are the iteration steps. This procedure converges to a local minimum or a saddle point Jm.
, where ε is a termination criterion between 0 and 1, whereas k are the iteration steps. This procedure converges to a local minimum or a saddle point Jm.
The algorithm is composed of the following steps:
|
Parameters of the FCM algorithm
Before using the FCM algorithm, the following parameters must be specified:
- the number of clusters, c,
- the fuzziness exponent, m,
- the termination tolerance, ε.
Advantage and Disadvantage
Advantages:
- Gives best result for overlapped data set and comparatively better than k-means algorithm.
- Unlike k-means where data point must exclusively belong to one cluster center here data point is assigned membership to each cluster center as a result of which data point may belong to more than one cluster center.
Disadvantages:
- Apriori specification of the number of clusters.
- With lower value of β we get the better result but at the expense of more number of iteration.
- Euclidean distance measures can unequally weight underlying factors.
Example 1

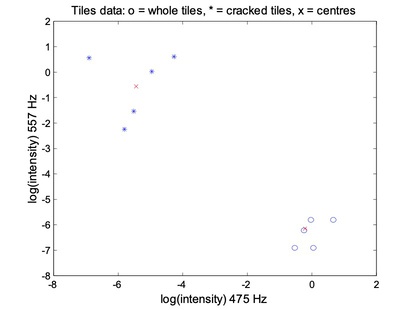
Tiles are made from clay moduled into the right shape, brushed, glazed, and baked. Unfortunately, the baking may produce invisible cracks. Operators can detect the cracks by hitting the tiles with a hammer, and in an automated system the response is recorded with a microphone, filtered, Fourier transformed, and normalised. A small set of data is given in above table.
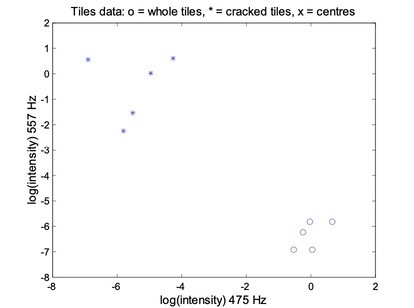
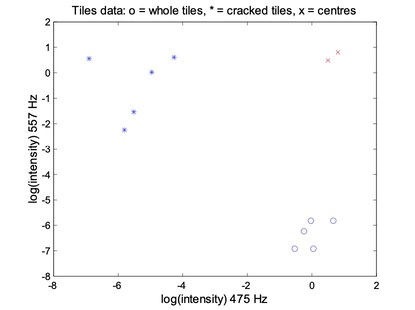
For the FCM, each data point belongs to two clusters to different degrees. Then,
- Place two cluster centres;
- Assign a fuzzy membership to each data point depending on distance;
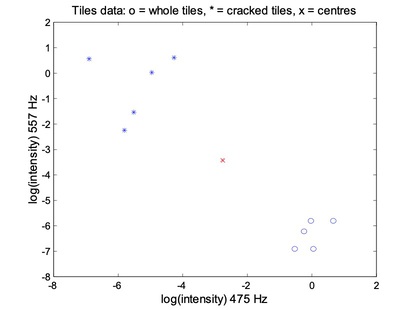
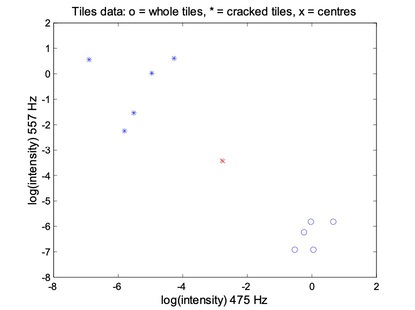
- Computer the new centre of each class;
- Move the crosses (x)
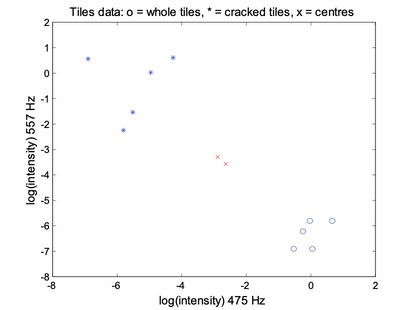
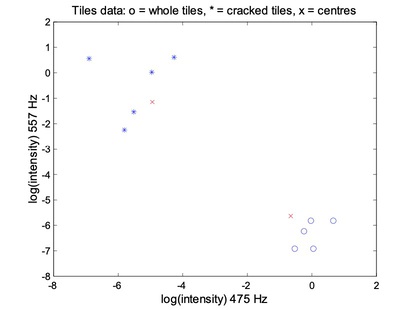
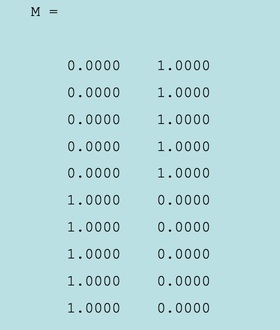
The membership matrix M:
- The last five data points (rows) belong mostly to the first cluster;
- The frist five data points (rows) belong mostly to the second cluster;
References & Resources
- http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/cmeans.html
- http://homes.dsi.unimi.it/~valenti/SlideCorsi/Bioinformatica05/Fuzzy-Clustering-lecture-Babuska.pdf
- https://sites.google.com/site/dataclusteringalgorithms/fuzzy-c-means-clustering-algorithm
Latest Post
- Dependency injection
- Directives and Pipes
- Data binding
- HTTP Get vs. Post
- Node.js is everywhere
- MongoDB root user
- Combine JavaScript and CSS
- Inline Small JavaScript and CSS
- Minify JavaScript and CSS
- Defer Parsing of JavaScript
- Prefer Async Script Loading
- Components, Bootstrap and DOM
- What is HEAD in git?
- Show the changes in Git.
- What is AngularJS 2?
- Confidence Interval for a Population Mean
- Accuracy vs. Precision
- Sampling Distribution
- Working with the Normal Distribution
- Standardized score - Z score
- Percentile
- Evaluating the Normal Distribution
- What is Nodejs? Advantages and disadvantage?
- How do I debug Nodejs applications?
- Sync directory search using fs.readdirSync