Version Control
Definition
The practice of tracking and providing control over the changes made to source code.
- The need for managing software versions has existed as long as there's been software.
- Version control is commonly used by a development team to keep track of the various pieces of source code that different members of the project are working on, along with various versions that they may wish to create.
Local Version Control
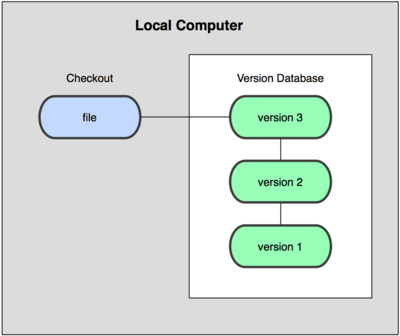
Look at the case of a single developer. With a single developer you've got a version control database here. And on that version control database, I show a couple of versions of this software of your local computer. This could be your file system or it could be a version control system database as well. Now what happens, if you want to check out file a, let's say from version two and edit it and change it, you make those changes and you stick it back into the file system. It's very easy for you do go and pull something, some other version, out of that version database. And so even as a single user, this is a common thing for folks to do is to save various versions of the software they're working on, in case they need to back up if they make a mistake. Or many cases, folks will, if they're creating new feature, they'll stick that into a different version until they get all of the various bugs associated with that feature worked out, and then they'll move onto the next version.
Centralized Version Control
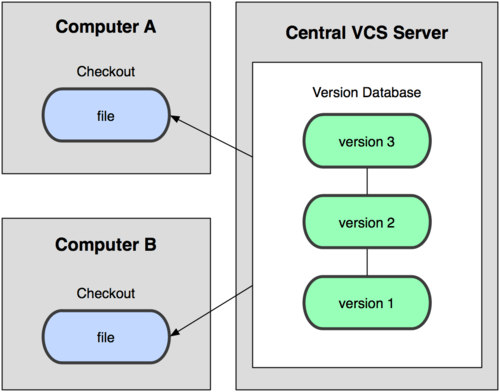
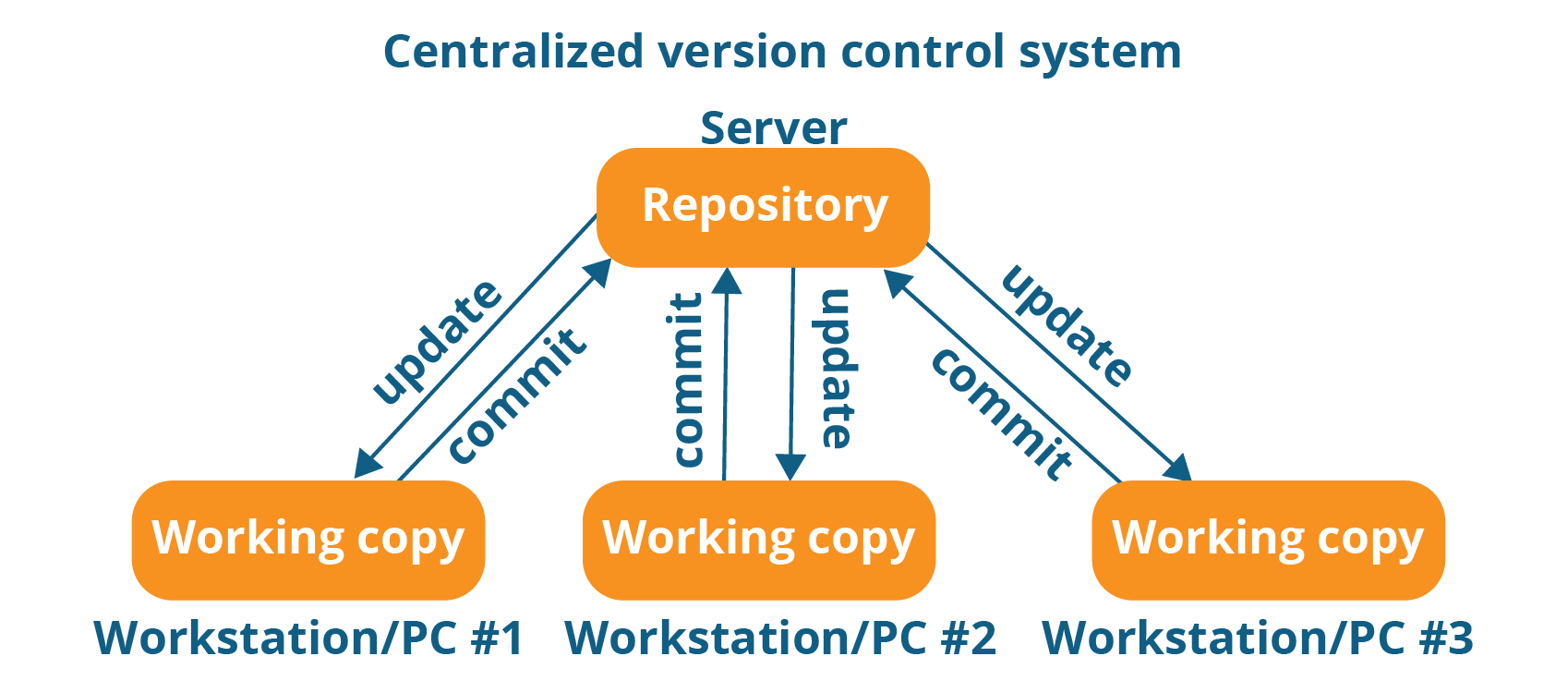
Now how about if you're part of a development team? If you're part of a development team it's very common to have a centralized version control server. this allows multiple developers to work at the same time. So here I show developer one has checked out file A from the second version of this project. Developer two, checked out file B. Generally what happens in centralized version control systems is, since developer one has checked out file A, developer b is prevented from working on it. That's a common, framework that people use with centralized version control system. So developer one, developer two can both work independently on different files, and check the back into the version control system at some point in time. Here's what that looks like, with centralized version control systems, you only need to store the differences between files from one version to the next. And so, here I'm showing version one is, consists of three files. Version two, only firle C was changed, and so there's the first change, and only that change is saved to the database, not the entire file. And in version three, the other two files are changed and so on and so forth until you get to last version
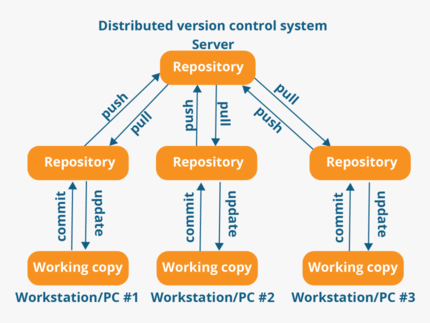
Distributed Version Control
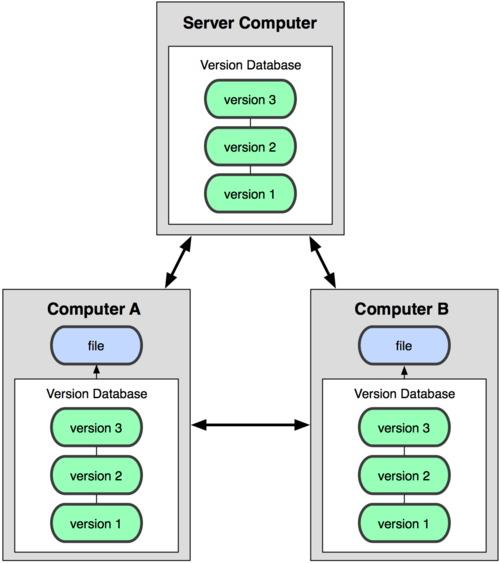
- As software development has become more team-based, and and teams have become more distributed, the need for distributed version control systems has emerged.
- In distributed version control, there is no centralized repository, team members don’t check out files from these systems, they check out the entire repository.
- This does not lock the repository — other team members can also download the current version of a project.
- Later, when a team member check the project back in, it is marked as a different version in the repository. Thus, you can think of distributed version control systems as storing different snapshots of a project over time.
- It is up to the owner of the repository to merge different version together if he/she so chooses
Latest Post
- Dependency injection
- Directives and Pipes
- Data binding
- HTTP Get vs. Post
- Node.js is everywhere
- MongoDB root user
- Combine JavaScript and CSS
- Inline Small JavaScript and CSS
- Minify JavaScript and CSS
- Defer Parsing of JavaScript
- Prefer Async Script Loading
- Components, Bootstrap and DOM
- What is HEAD in git?
- Show the changes in Git.
- What is AngularJS 2?
- Confidence Interval for a Population Mean
- Accuracy vs. Precision
- Sampling Distribution
- Working with the Normal Distribution
- Standardized score - Z score
- Percentile
- Evaluating the Normal Distribution
- What is Nodejs? Advantages and disadvantage?
- How do I debug Nodejs applications?
- Sync directory search using fs.readdirSync